エグゼクティブサマリー
臨床試験が失敗する原因は、チームに専門知識や意欲、テクノロジーが欠けているからではありません。 失敗の本質は、現実の運用を支えるには不十分なデータに基づいて、重要な意思決定が早すぎる段階で行われてしまうことにあります。
プロトコル設計、実現可能性評価、治験施設の選定、被験者募集など、臨床チームは複雑さを増す中で、より迅速な対応を求められています。しかし、その意思決定を支える基盤――つまりデータ――は、断片的で過去志向、あるいは十分に検証されていないことが多いのです。
本eBookでは、臨床開発におけるデータ品質のギャップについて掘り下げます。なぜ「より多くのデータ」や「高度な分析」へのアクセスが、より良い成果につながっていないのか。そして、常に自信を持って実行可能な意思決定を行うチームの違いは何なのか。
その違いはツールではありません。それは「意思決定に備えたデータ」です――最も重要な場面で明確さをもたらし、インサイトを行動に変えることができるデータです。
問題は想像以上に早く始まっている
あなたの試験は実施段階で失敗したのではありません。もっと早い段階で失敗していたのです。被験者登録が停滞し、スケジュールが遅れ、プロトコルの修正が繰り返されるとき、その原因はしばしば「運用上の摩擦」として説明されます。しかし、実際にはこれらは症状であり、原因ではありません。
多くの試験は、強固な科学的根拠と善意をもって設計されています。しかし、次の点について十分な可視性を持たずに計画されることが少なくありません。
- 該当する患者が実際に十分な数存在するのか
- 選定された施設が現実的にその患者にアクセスできるのか
- 想定されたタイムラインが現実世界の条件を反映しているのか
その結果、実現可能性の問題は試験がすでに進行してから明らかになります――変更には時間とコストがかかり、リスクも高まります。
業界データはこのパターンを明確に示しています。プロトコル修正は増加し続け、募集の遅延は広く見られ、登録不足の施設も珍しくありません。これらは単発の失敗ではなく、現実の複雑さに耐えられないデータに基づいて早期に行われた意思決定を示しています。
不都合な真実はこうです:多くの試験が失敗するのは、データが不足していたからではありません――そのデータが「十分に良い」と誰も自信を持って言えなかったからです。
なぜ“より多くのデータ”では問題を解決できなかったのか
業界は「データ不足」に悩んでいるわけではない 臨床チームは、過去の試験記録、レジストリデータ、施設情報、リアルワールドデータ、そしてそれらに重ねられた分析など、かつてないほど膨大なデータにアクセスできます。
それにもかかわらず、成果は同じペースで向上していません。
今日、試験計画に使われるデータの多くは次のような特徴を持っています。
- 不完全、または不統一なキュレーション
- 意思決定に特化しておらず、過去志向
- ワークフロー間で分断されている
- 解釈や検証が難しい
こうしたデータを複雑な意思決定に利用したり、高度な分析やAIモデルに投入したりすると、精度が高いように見える“錯覚”を生みます。アウトプットは洗練されていても、その前提は脆弱なままです。 データが増えても、明確さは自動的には得られません。質とコンテキストがなければ、ただノイズが増えるだけです。
「意思決定に備えたデータ」とは何を意味するのか
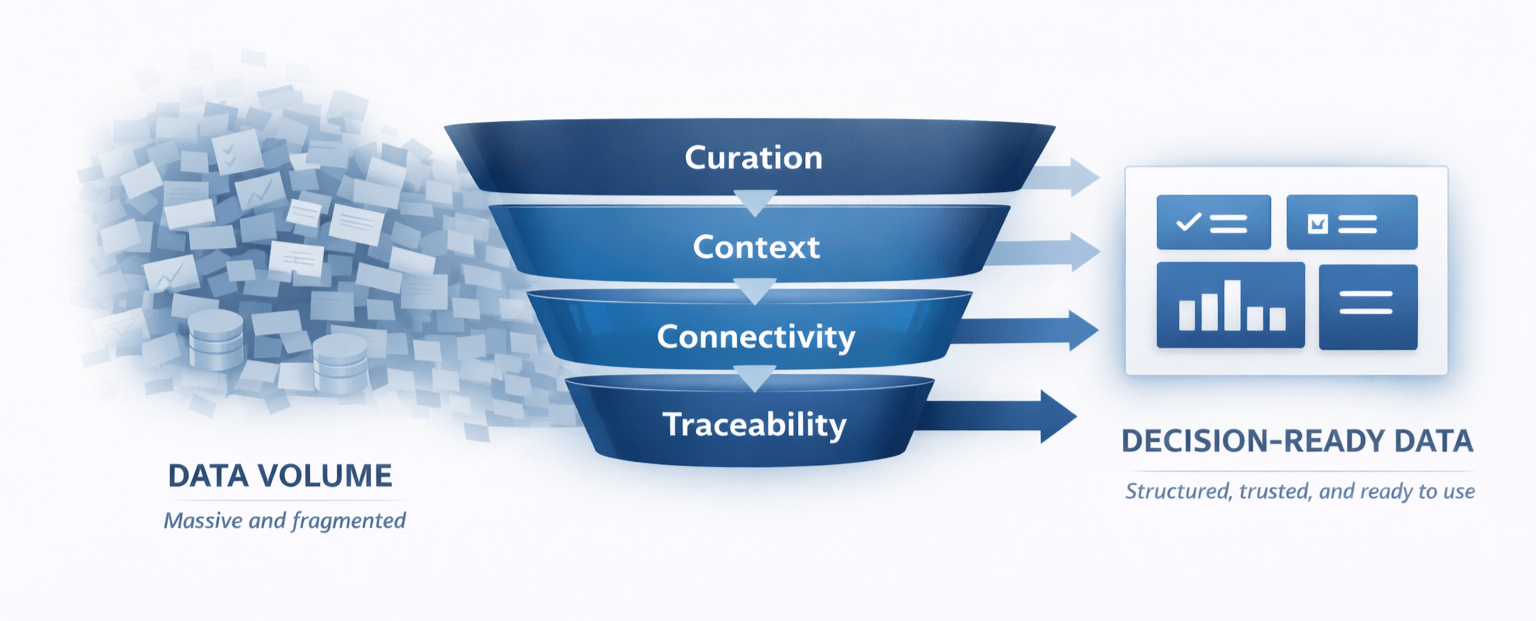
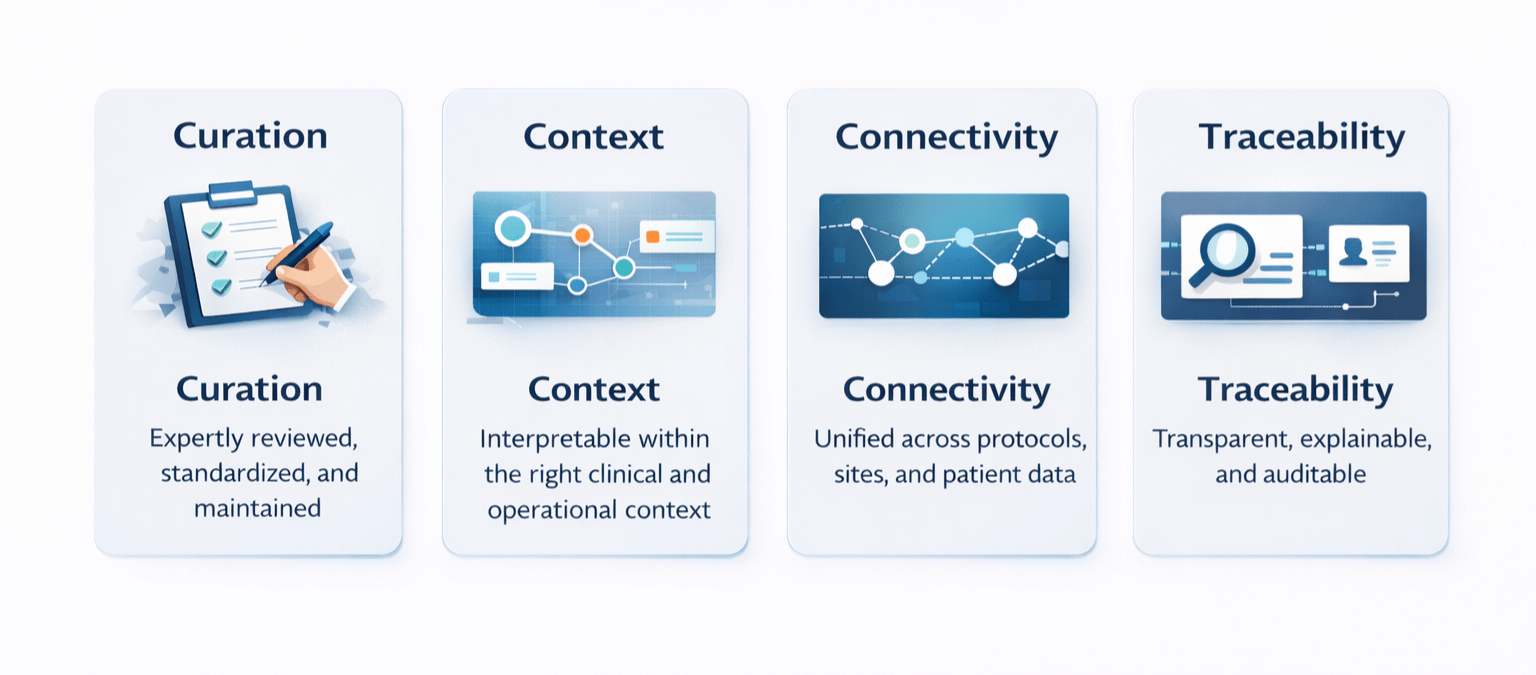
高品質な臨床インテリジェンスは、データの量ではなく、どれだけ信頼性をもって意思決定を支えられるかで定義されます。意思決定に備えたデータは、次の4つの基盤に支えられています。
- キュレーション: データは専門家によって積極的にレビューされ、標準化され、維持される必要があります。単なる集約では、ノイズがシグナルを覆い隠します。
- コンテキスト: 試験データ、施設のパフォーマンス、患者の可用性は、相互に関連付けて解釈できなければなりません。個別に評価すると、意思決定は崩れます。
- コネクティビティ: プロトコル設計、実現可能性評価、施設選定、被験者募集は別々のステップではありません。これらは連動するシステムであり、データもその現実を反映する必要があります。
- トレーサビリティ: 推奨や予測がなぜ存在するのかをチームが理解できること。説明できないデータは信頼できません。特に規制環境ではなおさらです。
これらの基盤がなければ、最先端の分析であっても、信頼できるインサイトを提供することは困難です。
データ品質が静かに意思決定を損なう場所
データ品質の低さは、あらゆる重要な意思決定の場面で目に見える影響を及ぼします。
- プロトコル設計: 組み入れ・除外基準は、その現実世界への影響を定量化しないまま確定されることが多いです。プロトコルは紙面上では理にかなっていても、運用面では非現実的であることが判明します。修正が続くのは、科学が変わったからではなく、実現可能性が最初から不明確だったからです。
- 実現可能性(フィージビリティ): 実現可能性は、継続的な検証プロセスではなく、一度きりのチェックポイントとして扱われがちです。初期の仮定は、条件が変化してもそのまま残ります。
- 施設選定: 施設は、経験や評判、利便性に基づいて選ばれることが多く、パフォーマンスや患者アクセスの測定可能な可能性に基づいていません。
- 患者募集: 募集戦略は「患者はどこかに存在する」という前提で立てられ、紹介ネットワークやケアパス、患者が実際に受診する場所を十分に考慮していません。
- 予測: タイムラインは、プロトコル固有の現実ではなく、平均値や類似事例に基づいて構築されます。信頼性は確率ではなく日付で表現されます。
意思決定に備えたデータで何が変わるのか
高パフォーマンスの臨床チームは、不確実性を排除するのではなく、異なる方法で管理します。この変化は理論ではなく、実践です。
Before(従来)
- プロトコルを確定し、その後に実現可能性を検証
- 施設リストは経験と空き状況から作成
- 募集リスクは試験開始後に発覚
- 予測は過去の平均値に依存
After(意思決定に備えたデータを活用)
- 組み入れ基準を実際の患者集団に照らして検証
- 設計の進化に合わせて実現可能性を継続的に確認
- 施設はアクセスとパフォーマンスの可能性に基づいて選定
- 募集リスクは事前に特定し、軽減策を講じる
- 予測はプロトコル固有の現実を反映し、汎用的なベンチマークに頼らない
結果は完璧ではありません。しかし、驚きは減り、インサイトは早期に得られ、分析から行動への移行に自信が持てるようになります。
AIの役割 ― そしてその限界
人工知能(AI)は、現代の臨床ワークフローに欠かせない存在となっています。分析を加速し、パターンを抽出し、大規模な意思決定を支援します。
しかし、AIは弱いデータを修正しません。それを増幅します。