Why Clinical Decisions Break Down — and How Leading Teams Restore Confidence
eBook
Clinical

Clinical trials rarely fail because teams lack expertise, intent, or technology.
They fail because critical decisions are made too early, on data that cannot support real-world execution.
Across protocol design, feasibility, site selection, and recruitment, clinical teams face mounting pressure to move faster while absorbing more complexity. Yet the foundations supporting those decisions — the data itself — often remain fragmented, backward-looking, or insufficiently validated.
This eBook explores the growing data quality gap in clinical development: why access to more data and more advanced analytics has not translated into better outcomes, and what distinguishes teams that consistently make confident, executable decisions.
The difference is not tools. It is decision-ready data — data that brings clarity where it matters most and allows insight to translate into action.
Your trial didn’t fail in execution. It failed much earlier.
When enrollment stalls, timelines slip, or protocols require repeated amendments, the root cause is often framed as operational friction. In reality, these issues are symptoms, not causes.
Most trials are designed with strong scientific rationale and good intentions. But they are frequently planned without sufficient visibility into:
As a result, feasibility issues emerge only after the trial is already in motion — when changes are expensive, slow, and risky.
Industry data reflects this pattern clearly. Protocol amendments continue to rise, recruitment delays remain widespread, and under-enrolling sites are common. These are not isolated failures. They point to decisions made early, using data that appeared adequate but could not withstand real-world complexity.
The uncomfortable truth is this: Many trials fail not because teams lacked data — but because no one could confidently say whether the data was good enough.
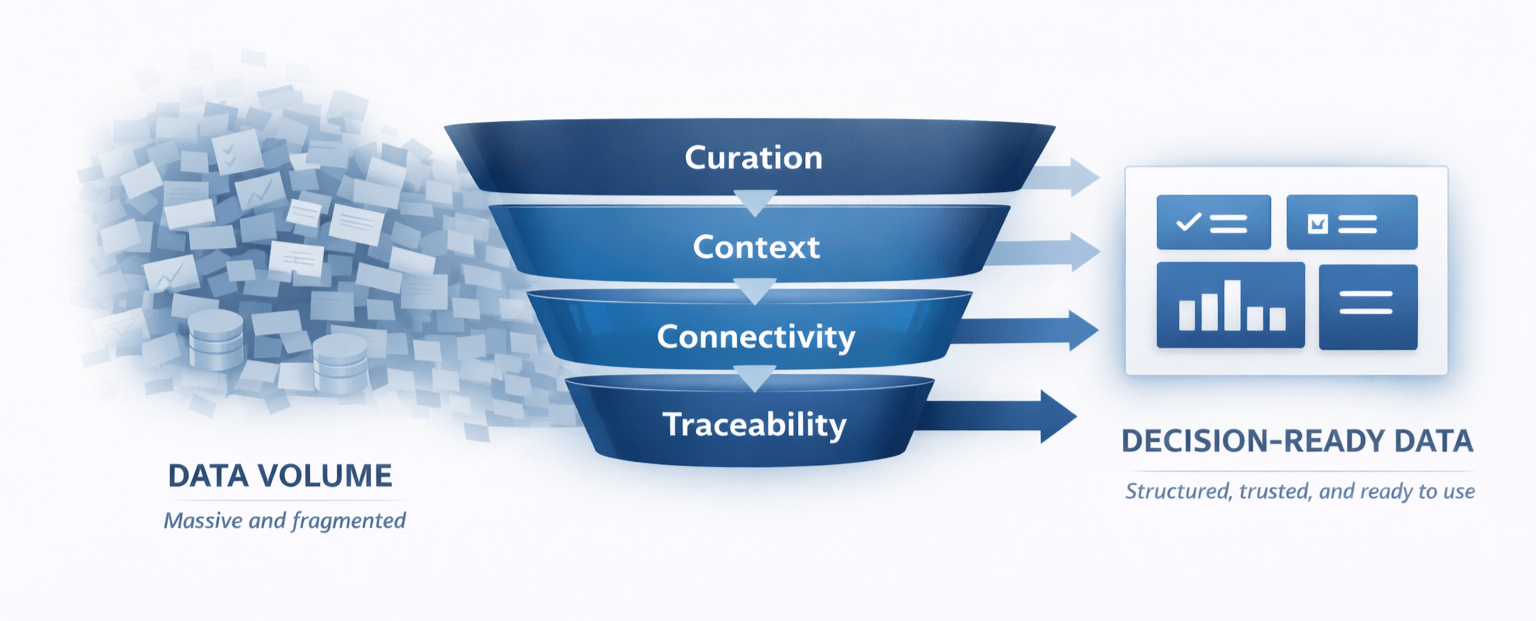
The industry does not suffer from a lack of data.
Clinical teams have access to unprecedented volumes of historical trial records, registry data, site information, real-world datasets, and analytics layered on top.
Yet outcomes have not improved at the same pace.
The reason is simple: volume does not equal quality.
Much of the data used in trial planning today is:
When this data is used to inform complex decisions — or fed into advanced analytics and AI models — it creates a false sense of precision. Outputs may look sophisticated, but the assumptions beneath them remain fragile.
More data does not automatically bring clarity. Without quality and context, it simply adds noise.
High-quality clinical intelligence is defined not by how much data you have, but by how reliably it can support a decision.
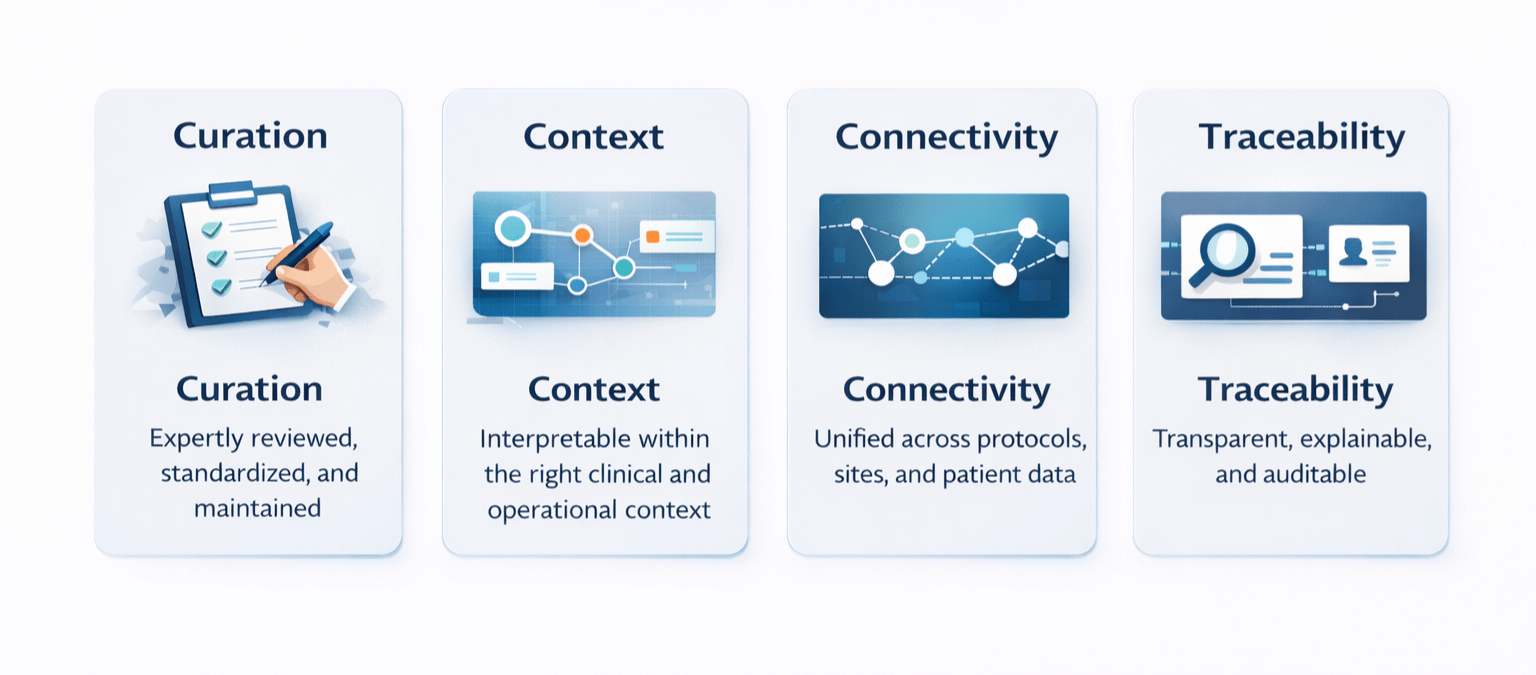
Decision-ready data rests on four foundations.
Without these foundations, even the most advanced analytics struggle to deliver reliable insight.
The impact of poor data quality becomes visible at every major decision point.
High-performing clinical teams do not eliminate uncertainty — they manage it differently.
The shift is not theoretical. It is practical.
Before
After
The result is not perfection. It is fewer surprises, earlier insight, and the ability to move from analysis to action with confidence.
Artificial intelligence (AI) has become an essential part of modern clinical workflows. It accelerates analysis, surfaces patterns, and supports decisions at scale.
But AI does not fix weak data. It amplifies them.

Models trained on fragmented, poorly curated, or disconnected data will produce outputs that appear precise but cannot be trusted. In high stakes, regulated environments, this lack of transparency quickly becomes a barrier to adoption.
Trustworthy AI depends on:
AI delivers value when it is built on data that is already decision-ready.
As trials grow more complex and expectations rise, the cost of weak decisions increases. Timelines compress, budgets tighten, and tolerance for failure shrinks.
In this environment, the advantage is not speed alone. It is confidence — the ability to act decisively because the data supports it.
Clinical leaders should ask:
Teams that can answer “yes” are not guessing less. They are deciding better.
Every clinical decision starts with data. But only decision-ready data can bring clarity and turn insight into meaningful action.
As AI becomes central to clinical development, the differentiator will not be algorithms alone — but the quality, connectivity, and trustworthiness of the data beneath them.
Bridging the data quality gap is not an abstract ambition. It is the foundation of trials that can actually be delivered.
To enable the booking feature, please enable all cookies in your browser.